
ISBN Extractor Chrome 插件, crx 扩展下载
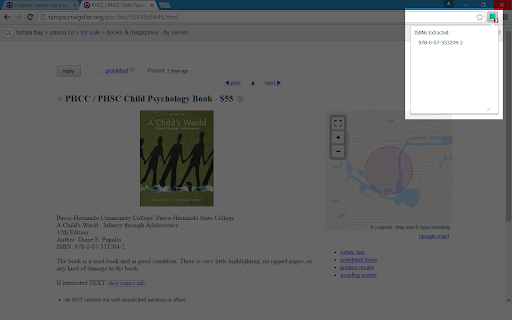
Automatically extract all ISBN from a webpage.
This is a simple extension that will extract all ISBN from any web page.
Extracts all 10 or 13 digit ISBNs (even if separated by spaces or -).
If you want to make the list comma separated or anything like that I recommend http://sortmylist.com/
**Update Version 1.1 **
Updated ISBN matching pattern.
ISBN scraping now is a bit cleaner
Updated to latest Google APIs
Fixed problem of not extracting after switching tabs
| 分类 | 📝工作流程与规划 |
| 插件标识 | bjillcfelggegochlahahhlfcgfmddip |
| 平台 | Chrome |
| 评分 |
☆☆☆☆☆
|
| 评分人数 | |
| 插件主页 | https://chromewebstore.google.com/detail/isbn-extractor/bjillcfelggegochlahahhlfcgfmddip |
| 版本号 | 1.1.2 |
| 大小 | 535KiB |
| 官网下载次数 | 449 |
| 下载地址 | |
| 更新时间 | 2022-04-23 00:00:00 |
CRX扩展文件安装方法
第1步: 打开Chrome浏览器的扩展程序
第2步:
在地址栏输入: chrome://extensions/
第3步: 开启右上角的【开发者模式】
第4步: 重启Chrome浏览器 (重要操作)
第5步: 重新打开扩展程序管理界面
第6步: 将下载的crx文件直接拖入页面完成安装
注意:请确保使用最新版本的Chrome浏览器